NVIDIA OSMO
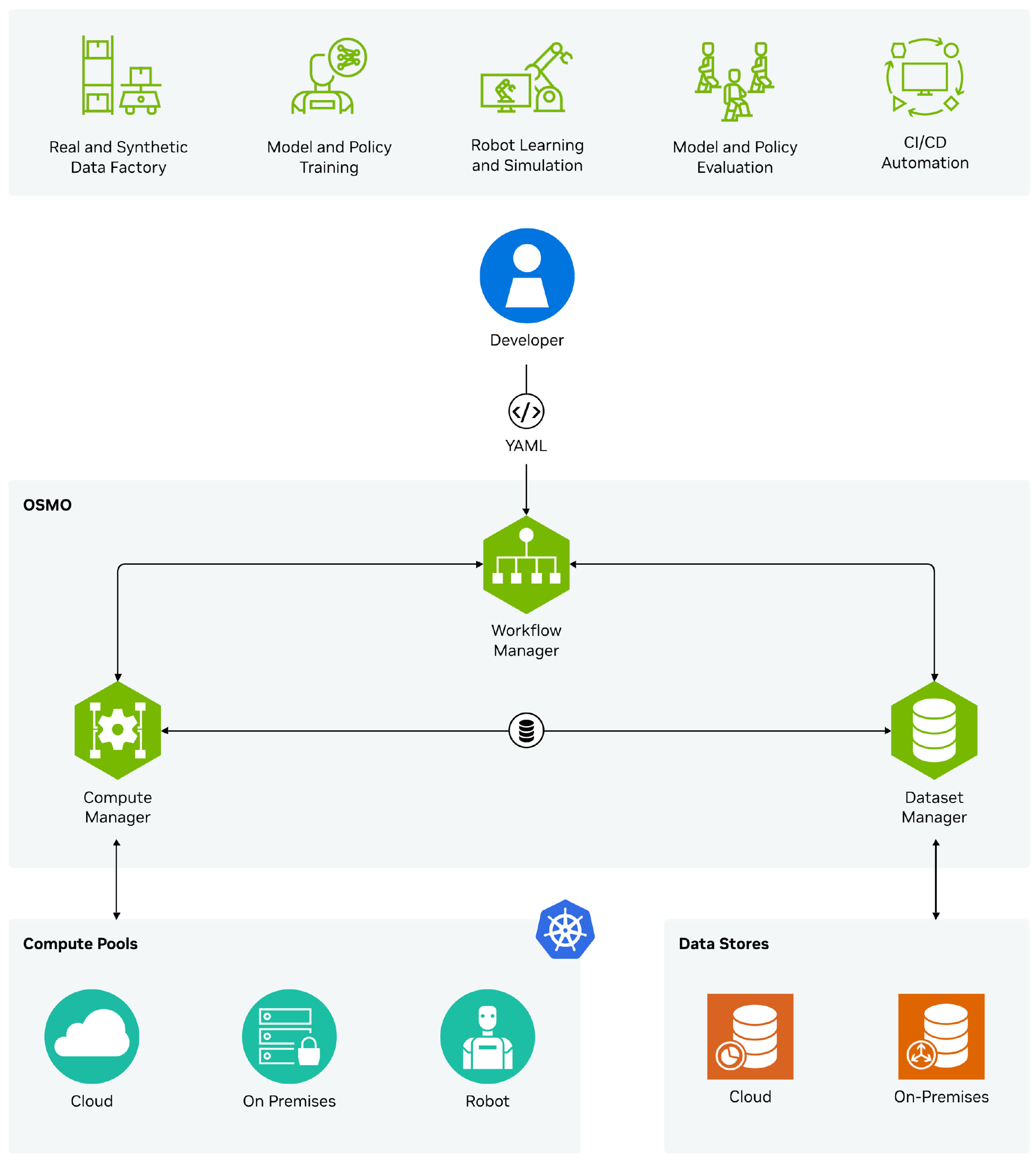
NVIDIA OSMO is an open-source, agentic operator enabling prompt-driven physical AI development. It unifies training clusters, simulation, and edge environments into a single YAML-defined engine that manages datasets, dependencies, and compute scheduling across cloud or on-prem infrastructure.
Delivered as a CLI with agent context files, OSMO turns your AI coding agent into a physical AI platform expert with full situational awareness over your development environment. Beyond just submitting jobs, your coding agent can also reason about your pipeline, query running workflows, inspect available GPU capacity, and monitor platform activity in real time.
Prompt to running pipeline, from synthetic data and training to SIL and HIL evaluation, no infrastructure expertise required.
How It Works
Define your entire physical AI pipeline in a single YAML file. OSMO handles the rest — scheduling across heterogeneous GPU clusters, resolving task dependencies, managing content-addressable datasets, and orchestrating workflows across cloud and on-prem infrastructure worldwide.
Delivered as a CLI with an agent context file for your favorite coding agent, it turns your coding agent into a physical AI infrastructure expert — able to reason about pipelines, query workflows, inspect GPU capacity, and act with real-time situational awareness.
Benefits of NVIDIA OSMO
OSMO lowers the barrier to the development of robotics by bringing the following benefits:
End-to-End Orchestration
Deploy a single no-code YAML workflow for eveything—from data generation to RL, training, and simulation validation—and share accelerated clusters across nodes for multi-stage runs with no Kubernetes experience.
Centralized Control Plane
Deploy and orchestrate multi-stage workloads on Kubernetes clusters supporting x86, Arm, and NVIDIA GPUs. These workloads are deployable on-premises and on major Cloud Service Providers (CSP).
Infrastructure Skills for Your Coding Agent
Agent-aware workflows can reason about pipelines, monitor execution, inspect capacity, and ensure traceable, auditable model deployment.
Secure With Open Standards
Secure your solution with OIDC for authentication, accounts, registries, storage, and secrets.
More Resources


Latest OSMO News
FAQs
1. What is NVIDIA OSMO used for?
OSMO is an open-source orchestrator purpose-built for physical AI. It lets developers build, run, and scale multi-stage workflows—including data generation, training, simulation, evaluation, and hardware-in-the-loop testing—across heterogeneous compute environments.
2. Does OSMO replace simulators or training frameworks?
No. OSMO orchestrates these components; it doesn’t replace them. It runs tools like NVIDIA Isaac Sim™, PyTorch-based training jobs, and reinforcement learning frameworks as part of an end-to-end workflow.
3. Can OSMO deploy models to production robots?
Not directly. OSMO prepares trained policies, datasets, and artifacts, but deployment into production systems is outside its scope. Users can integrate OSMO outputs with their preferred deployment runtime or robotics stack.
4. Is OSMO an MLOps platform?
No. OSMO doesn’t include experiment dashboards, artifact registries, or pipelines-as-code interfaces. Its role is focused on workflow execution, dataset versioning, data lineage, and compute orchestration for physical AI development.
5. Where can OSMO run? Is it limited to cloud environments?
OSMO isn’t vendor-locked. It supports on-prem clusters, cloud providers such as AWS, Azure, and GCP, multi-cloud environments, NVIDIA Jetson™ and ARM edge hardware, and mixed compute setups. Workloads can be scheduled across all of these.
6. Do I need Kubernetes or infrastructure expertise to use OSMO?
No. Workflows are defined in simple YAML files, and OSMO abstracts the underlying infrastructure. Users don’t need to write Kubernetes manifests or manage cluster configuration to run physical AI workloads at scale.
7. Why should I use OSMO instead of SLURM?
SLURM is a general-purpose HPC job scheduler. OSMO is purpose-built for physical AI and robotics workflows, which require dataset management, simulator integration, heterogeneous hardware, and multi-stage pipelines that SLURM isn’t designed to handle.